Google Inception v1 (GoogleLeNet)
요즘 한 프로젝트에 참여하게 되면서 신경망을 구축하고 있다.(처음이라 굉장히 삽질을 많이 하고 있음)
현재 Resnet모델을 참고하여 하이퍼파라미터값을 바꿔가면서 다양한 실험을 하고 있다.
어느 지점부터 train데이터에 대한 loss와 validation 데이터에 대한 loss 모두 떨어지지 않고 있어서 모델을 바꿔야 하나 고민하던 중, Inception 모델을 발견했다.
우선 딥러닝은 일반적으로 망이 깊고, 레이어가 넓을 수록 성능이 좋다고 한다.
하지만 네트워크를 크게 만들수록 파라미터가 많이 늘어나고, 망이 늘어 날 때마다 연산량이 많아지므로 여러가지 문제가 발생한다.(Gradient vanishing, overfitting 등)
이를 해결하기 위한 방안 중 하나가 'Sparse Connectivity'이다.
Sparse Connectivity는 노드간의 연결을 줄이는 것이다.

위처럼 모든 노드에 연결되어 있지 않고, 높은 관련성을 가진 노드들 끼리만 연결하도록 한 것이다.
이는 Fully connected network에서 사용하는 Dropout과 비슷할 것처럼 보인다.
하지만, Dense보다 Sparse Matrix연산이 더 나은 것이 없었고, Dense Matrix의 연산 기술은 발전한 반면에 Sparse Matrix연산은 발전이 더뎠다.
구글은 '어떻게 노드간의 연결은 Sparse하게 하면서 Matrix연산은 Dense연산을 하도록 처리하게 할 수 있을까?'하고 고민했다. 그리고 그 결과가 'Inception Module'이다.

- 1*1 conv
- 1*1 conv -> 3*3 conv
- 1*1 conv -> 5*5 conv
- 3*3 maxpool -> 1*1 conv
입력값에 대해 위 4가지 종류의 연산을 수행하고 4개의 결과를 채널방향으로 합친다.
그리고 위 모듈이 한 모델에 9개가 있다.
Inception module의 핵심 : 1*1 Convolution
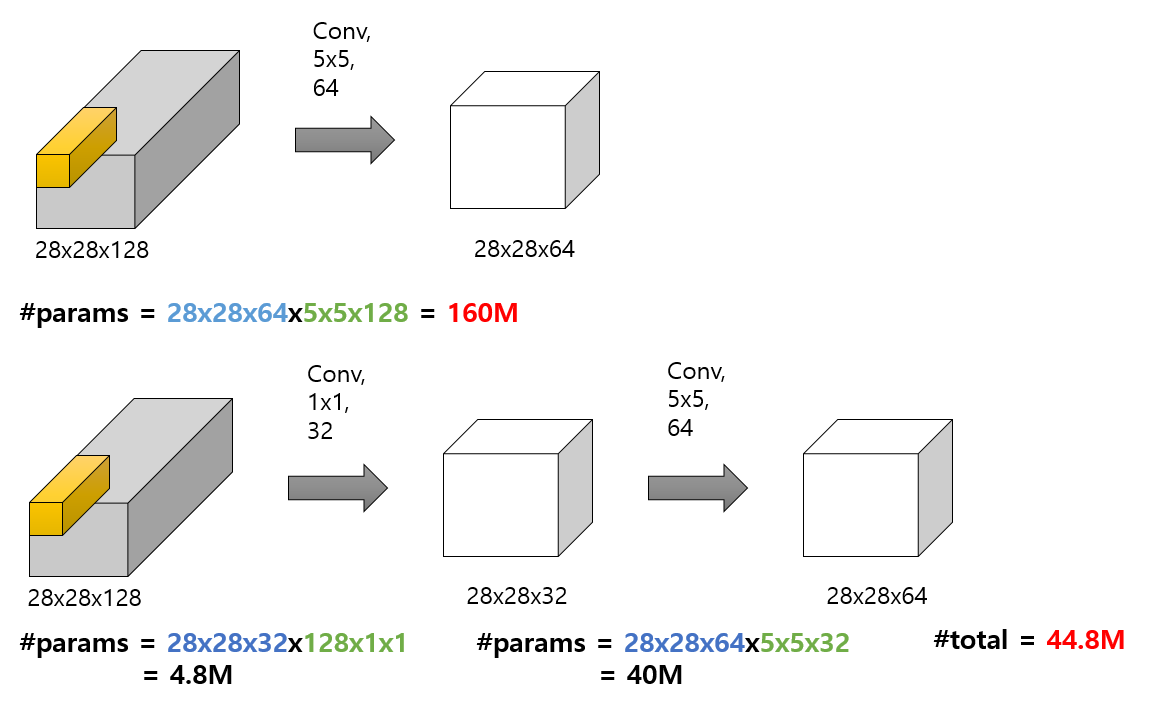
위처럼 똑같은 output을 만드는데 1*1 conv를 거친것과 거치지 않은 것의 파라미터 수의 차이는 어마어마하다.
즉, 이처럼 1*1 conv를 사용하면 채널 조절을 통해 파라미터 개수를 절약하여 기존 CNN구조보다 더욱 깊게 만들 수 있다.
*파란색: conv 후 결과값에서 사용되는 파라미터 수
*초록색: conv 과정에서 사용되는 필터가 가지는 파라미터 수
*빨간색: 위 과정에서 사용되는 총 파라미터 수
Inception module code
def inception_module(x, o_1=64, r_3=64, o_3=128, r_5=16, o_5=32, pool=32):
"""
# Arguments
x : 입력이미지
o_1 : 1x1 convolution 연산 출력값의 채널 수
r_3 : 3x3 convolution 이전에 있는 1x1 convolution의 출력값 채널 수
o_3 : 3x3 convolution 연산 출력값의 채널 수
r_5 : 5x5 convolution 이전에 있는 1x1 convolution의 출력값 채널 수
o_5 : 5x5 convolution 연산 출력값의 채널 수
pool: maxpooling 다음의 1x1 convolution의 출력값 채널 수
# returns
4 종류의 연산의 결과 값을 채널 방향으로 합친 결과
"""
x_1 = layers.Conv2D(o_1, 1, padding='same')(x)
x_2 = layers.Conv2D(r_3, 1, padding='same')(x)
x_2 = layers.Conv2D(o_3, 3, padding='same')(x_2)
x_3 = layers.Conv2D(r_5, 1, padding='same')(x)
x_3 = layers.Conv2D(o_5, 5, padding='same')(x_3)
x_4 = layers.MaxPooling2D(pool_size=(3, 3), strides=1, padding='same')(x)
x_4 = layers.Conv2D(pool, 1, padding='same')(x_4)
return layers.concatenate([x_1, x_2, x_3, x_4])<주의할 점>
- strides = 1
- padding = 'same'
'
GoogleLeNet 각 Layer 구조

처음에 바로 Inception module을 적용하지 않고 conv와 max pool로 사이즈를 줄인다.
그리고나서 Inception을 적용하고 중간중간 max pool로 사이즈를 줄여나간다.
마지막에는 average pool을 이전의 feature map크기와 같은 커널 사이즈로 적용하여 1000개의 class에 대한 예측을 수행한다.
포인트는,
- 처음에는 일반적인 CNN처럼 conv, max pool을 수행하고 중간에 Inception module을 적용하는 것
- Inception module 중간에 max pool을 적용하는 것
- 마지막에 avg pool과 dropout을 수행하여 fully connected layer의 파라미터 수를 줄여 주는 것
내용 및 이미지 참고)
https://ahmedbadary.github.io/work_files/research/dl/archits/convnets
https://datascienceschool.net/view-notebook/8d34d65bcced42ef84996b5d56321ba9/
https://kangbk0120.github.io/articles/2018-01/inception-googlenet-review
https://datascienceschool.net/view-notebook/8d34d65bcced42ef84996b5d56321ba9/